切换模式
使用selenium库中的webdriver爬取100ppi的数据

建立管道
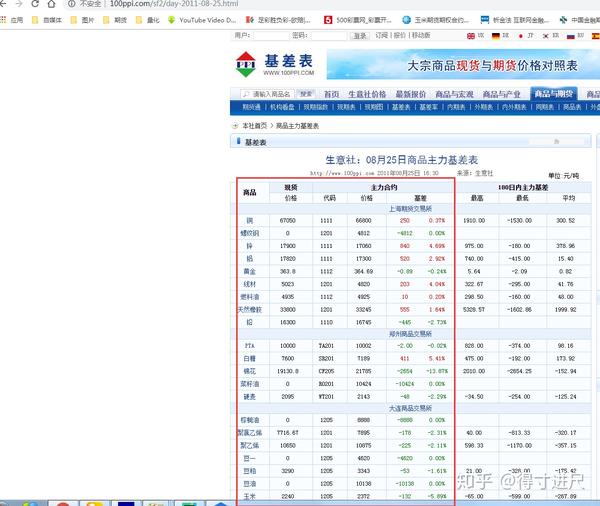
因为本人做期货量化,经常需要用到基差,需要经常去生意社看基差的数据。也就是如下的目标网址:
...
http://www.100ppi.com/sf2/day-2011-08-25.html,
http://www.100ppi.com/sf2/day-2011-08-26.html,
http://www.100ppi.com/sf2/day-2011-08-27.html,
...
网址中的日期是变化的,如果是工作日通常是有数据的,如果是非工作日则 无数据。
因为这个网址上的数据是动态的,是无法用requests爬取的,通常只能用webdriver模拟浏览器爬取。
下面我们就来把左边六列的数据爬下来。

import pandas as pd
import numpy as np
from selenium import webdriver
import datetime
import re
import time
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver',options=options)
url="http://www.100ppi.com/sf2/day-"
start_date=datetime.date(2018,1,1)
df_final=pd.DataFrame(columns=["品名","现货价","主力合约","主力合约价格","基差","基差率"])
for i in range(500):
dlt=datetime.timedelta(days=i)
offset=str(start_date+dlt)
url=url+offset+".html"
# print(url)
driver.get(url)
x=driver.find_elements_by_xpath("//tbody")[1].text.replace("上海期货交易所","").replace("大连商品交易所","").replace("郑州商品交易所","").replace("\n"," ").replace(" "," ")
index=x.find("铜")
if index<0:
url = "http://www.100ppi.com/sf2/day-"
continue
x=x[index:]
c=re.compile("\D+")
r=set(re.findall(c,x))
r.discard(" ")
r2=set()
for e in r:
e=e.strip("%").strip()
r2.add(e)
r2.discard("")
r2.discard(".")
r2.discard('-')
for e in r2:
x=x.replace(e,"\n"+e)
y=x.split("\n")
if "" in y:
y.remove("")
ll=[]
for e in y:
e=e.split()[:6]
ll.append(e)
if [] in ll:
ll.remove([])
df=pd.DataFrame(data=ll,columns=["品名","现货价","主力合约","主力合约价格","基差","基差率"])
df["基差率"] = df["基差率"].str.strip('%').astype(float) / 100
df.sort_values(by="基差率",ascending=False)
df["日期"]=offset
print(df)
url="http://www.100ppi.com/sf2/day-"
df_final=df_final.append(df,sort=False)
time.sleep(3)
df_final.reset_index(drop=True)
print(df_final)
df_final.to_csv("jc.csv")上面的代码是可以直接在python3环境下运行的,但是需要把chrome的webdriver下载下来并放到python3的解释器同一个文件夹下。
因为上面的表格非常不规则,另外还经常数据缺失,处理过程稍微有点复杂,需要用到pandas,datetime,正则表达式re模块。
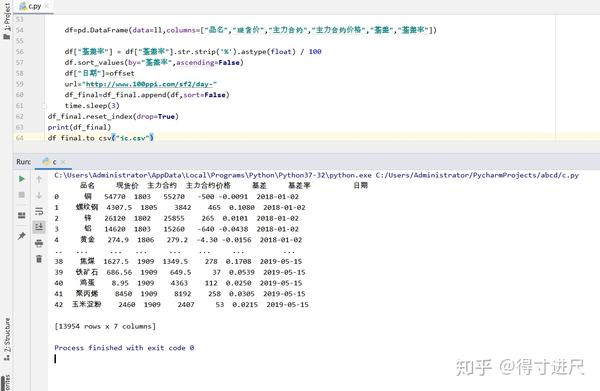
最后运行的结果是这样的:

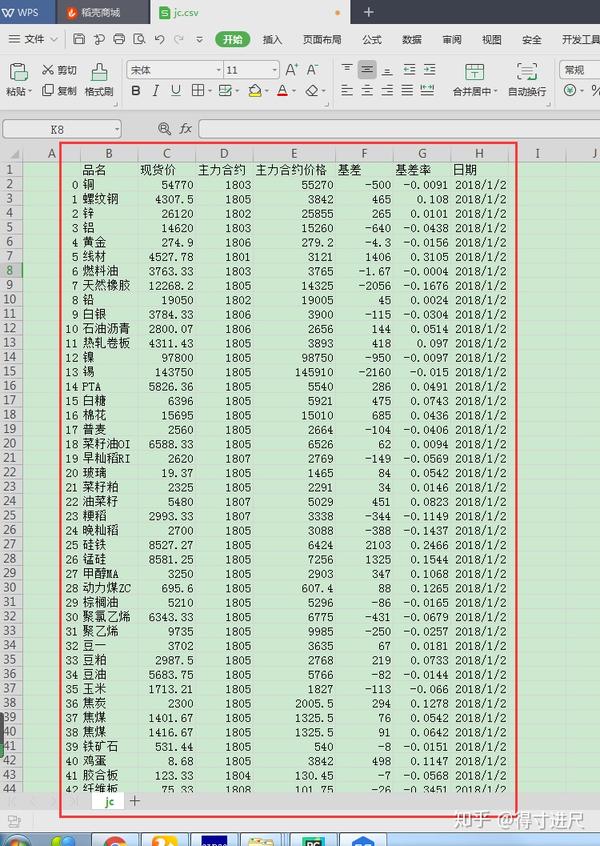
最后拿到的csv文件是这样的:

发布于 2019-08-28 21:11
python爬虫
编程
量化