切换模式

数据分析之数据爬取

未知
爬虫原理
- 什么是爬虫?
爬虫,即网页爬虫,又可称为网络蜘蛛。通俗的讲,网络蜘蛛是通过网页的URL来获取网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面抽取新的URL放入队列,然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
- 网络爬虫流程
模拟浏览器发送请求(获取网页代码)->获取响应内容->解析内容->保存数据(存放于数据库或文件中)
爬虫实践
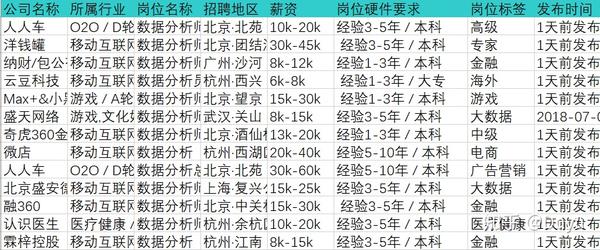
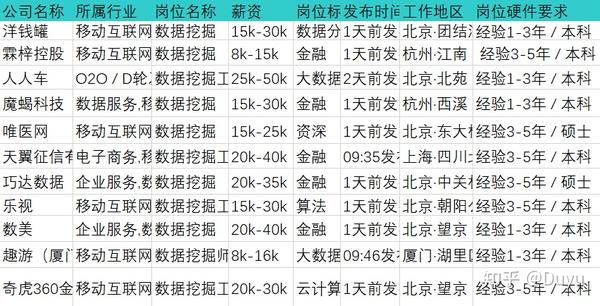
数据来源:某招聘网站上数据分析和数据挖掘岗位信息
爬取手段:某爬虫工具
爬取字段:招聘公司;招聘地址;岗位要求;薪资水平等
部分爬取结果如下所示:


初级数据分析学习计划
第一周:数据爬取,初步了解爬虫原理。学会用爬虫工具进行简易数据爬取,进阶阶段再通过编程实现。
第二周:概率统计知识回顾与巩固。
第三周:掌握Excel对数据进行清洗,整理和分析等工作。
第四周:复习sql语法,并用sql对数据进行分析。
第五周:学习数据可视化,熟悉常用的可视化工具以及完善ppt的制作。
第六周:整理自己的项目报告。
编辑于 2018-07-06 12:26
大数据
数据挖掘