点击率预测问题建模(三)

前面两篇文章主要介绍了一下CTR模型的建模思路跟交叉特征的构造方法,本篇文章重点对比下三种建模思路下不同的机器学习算法的优劣。这个时候就能看出我们前面构造的那个广告点击过程的作用了,我们可以不断地回测各种模型的效果。谈到效果,真正用于生产的CTR模型的优化目标其实不是最大化整体的点击率,而是最大化整体的收益。对我们广告系统来说,一个广告点击率低没关系,只要广告主愿意出钱,我们也可以优先展示它。假设某广告主愿意为广告的每次点击出价b元,我们的CTR模型对这个广告的点击率预估是p,那么展示了这个广告之后我们的预期收入就是 b*p 元。从这个意义上讲,在CTR场景下,广告优劣的排序其实不重要,把点击率给预测准才是最重要的,因为如果使用预期收入排序,就相当于把预测误差也给放大了b倍。
再谈一下我们人工构造的广告点击过程,我们可以使用产生训练数据同样的方法产生一些validation数据,由于我们掌握着广告点击的神谕(oracle),根据这个oracle我们可以完美地预测用户对每个广告的点击率,于是预期收入就有了一个上限,对比模型效果跟这个上限的差距就可以看出模型的提升空间。
先来研究下三种建模思路的优劣,分别对三种思路使用LR:针对思路一我们使用LR构造一个二分类器;针对思路二,我们对每个广告构造1个二分类器,得到三个模型,并使用它们分别预测三个广告的点击率;针对思路3,把数据分成4个类构造一个soft-max多分类器。为了排除不同的广告出价对模型效果的影响,我们重复进行40次试验,每次都随机生成一组广告点击出价。回测的结果如下:


在这组数据中,实际收入越高说明模型的点击率的估计越准。
- 对比多模型LR跟softmax,可以发现它们的效果差不多,说明思路二跟思路三的合理程度近似
- 对比原始特征下的多模型LR跟交叉特征下的多模型LR,可以发现特征工程对LR算法效果显著
- 对比交叉特征下的单模型LR跟多模型LR,可以发现单模型LR的效果要好一些。说明思路一的建模思路更为合理
把分类器换成100棵树的随机森林跟100棵树的GBDT进行回测,得到下面这组数据:
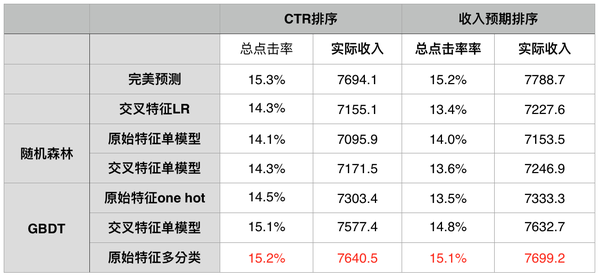

- 随机森林跟GBDT用直接使用单模型onehot encode也不会退化为热度模型。
- GBDT效果拔群,不做特征也比LR做了特征工程效果好。
- 无论算法选择什么,交叉特征都是有作用的。
- 用GBDT多分类模型居然可以进一步提升预期收入。
总结:算法复杂度的提升确实能够带来效果的提升,尤其是GBDT,捕捉特征的能力跟拟合能力都超强,以后做模型可以优先考虑GBDT,效果拔群。但是算法复杂度的提升也带来了CTR预测开销的提升,用于生产需要比较强的后台能力来帮助优化实时预测开销,不具备这种工程能力就只能折腾特征工程了。最后那组试验,GBDT多分类模型居然能进一步提升了效果,实力打脸前面的结论:思路一的假设更为合理。这种方法下甚至连交叉特征都不需要,就已经接近完美预测了(多分类模型再用交叉特征太麻烦了,偷懒没做,给GBDT的能力留个悬念)。作者把它放在这里的目的就是为了提醒大家,模型调优工作还是要靠trial and error,不管白猫黑猫,能抓到老鼠就是好猫。
声明:转载请联系作者,代码都是python+sklearn需要代码的同学请在评论里留下邮箱