jieba分词流程之DAG、Route
结巴分词是基于python的开源分词工具。在其根目录下的结构为
jieba功能介绍:
- 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
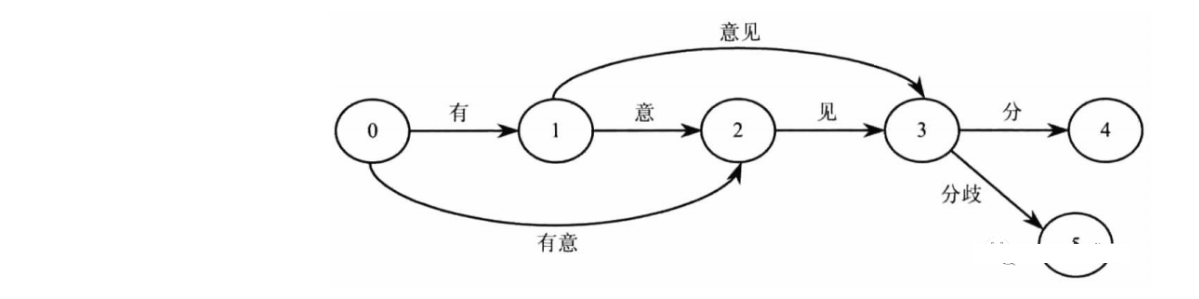
结巴分词流程图
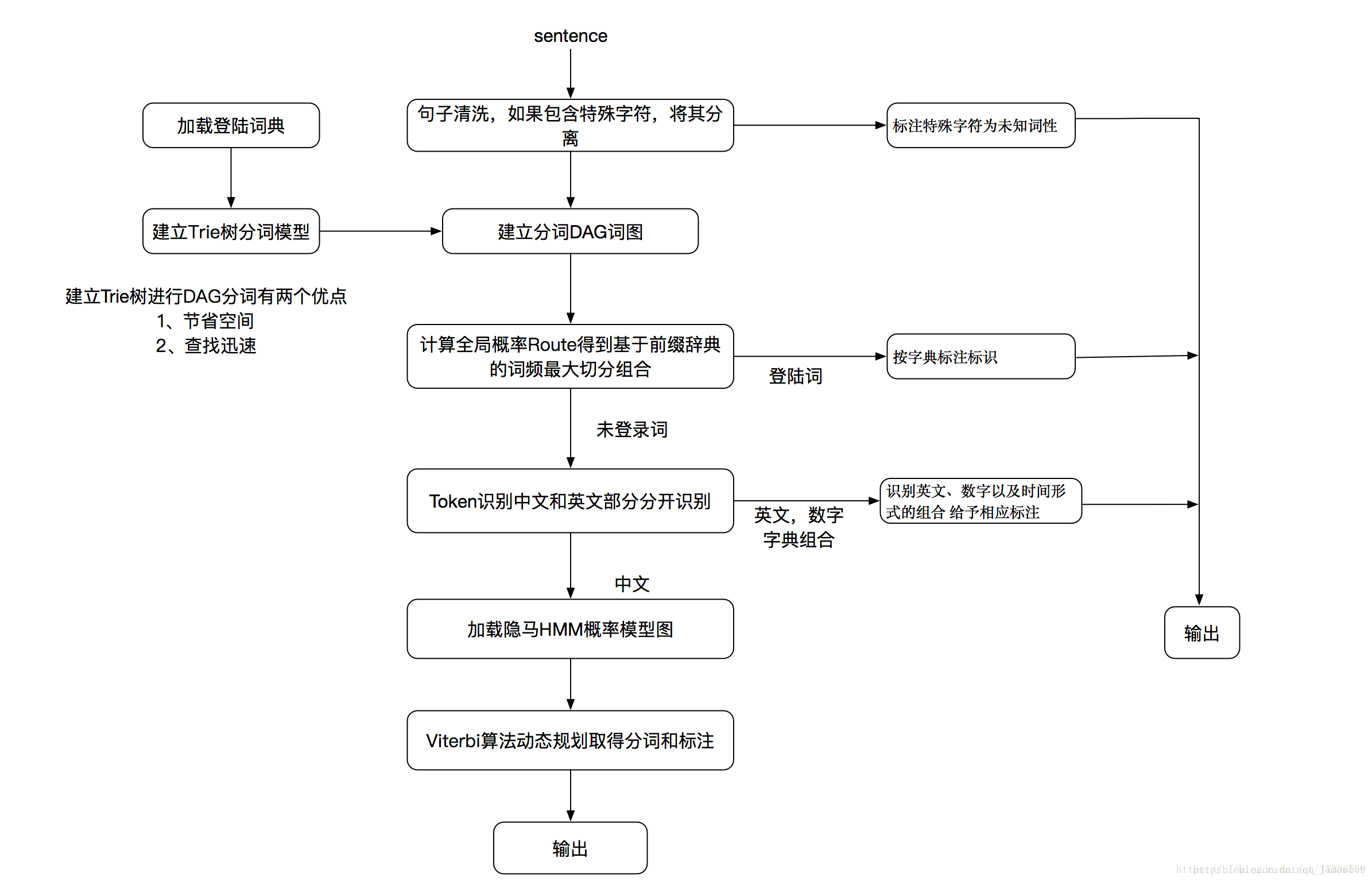
结巴分词从流程图中可看到分为两部分,一个是登录词的分词,另一个是未登录词的分词。什么是登录词呢?其实就是词库,例如jieba工程下的dict.txt,就是词库,也就是登录词,打开可看到有三列,例如“B超 3 n”, 第一列是词,第二列是词频,第三列是词性。
先查看下登录词是怎么分词的,从流程图中可看到,是通过建立DAG词图和计算全局概率Route分词的。
建立DAG词图
在jieba目录的test新建一个test.py,我们调试下DAG的构建,测试sentence=”我们一起学猫叫”,运行结果为:{0: [0, 1], 1: [1], 2: [2, 3], 3: [3], 4: [4], 5: [5, 6], 6: [6]},这个字典即为DAG,key为字所在的位置,value为从字开始能在FREQ中的匹配到的词末尾位置所在的list。句子中的第一个字为’我’,所在位置即key为0,FREQ会在get_DAG方法中做介绍。
get_DAG(sentence) 函数功能为把输入的句子生成有向无环图,
#encoding=utf-8
from __future__ import unicode_literals
import sys
sys.path.append("../")
import jieba
import jieba.posseg
import jieba.analyse
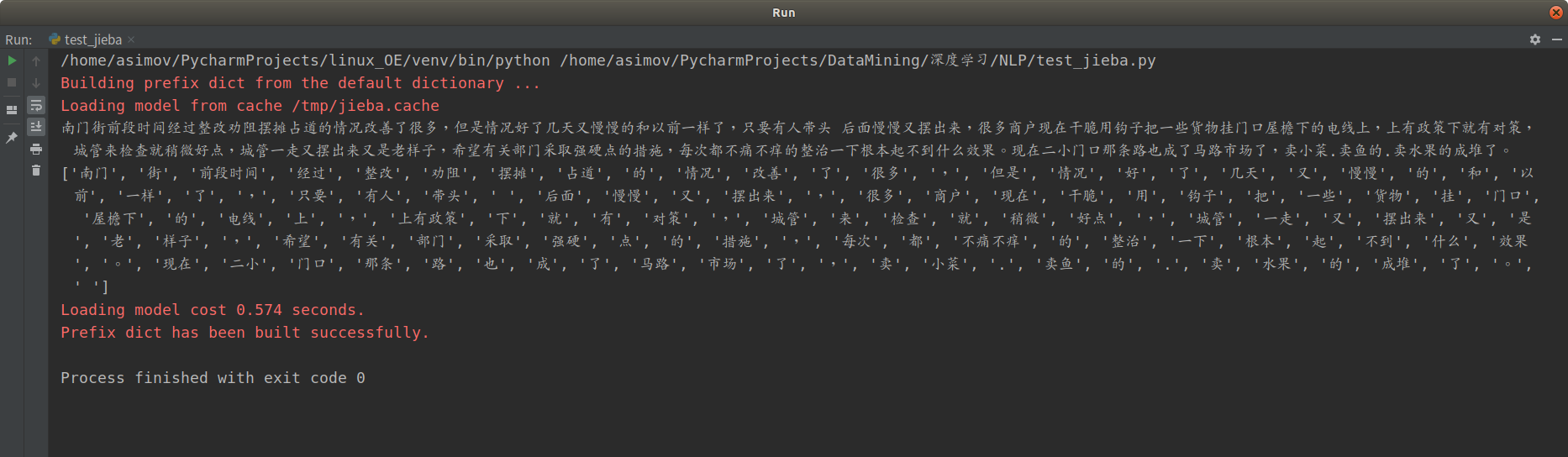
sentence="我们一起学猫叫"
sentence_dag = jieba.get_DAG(sentence)
print(sentence_dag)
route = {}
jieba.calc(sentence, sentence_dag, route) # 根据得分进行初步分词
print(route)
seg_list = jieba.cut(sentence)
print(", ".join(seg_list))
运行结果

接下来,我们查看get_DAG,找到jieba根目录中init.py中,这里描述了结巴分词的核心代码。jieba分词接口主入口函数,会首先将输入文本解码为Unicode编码。
def get_DAG(self, sentence):
self.check_initialized()
DAG = {} #DAG空字典,用来构建DAG有向无环图
N = len(sentence) #赋值N词的长度
for k in xrange(N): #创建N词长度的列表,进行遍历
tmplist = [] #从字开始能在FREQ中的匹配到的词末尾位置所在的list
i = k
frag = sentence[k] #取传入词中的值,例如k=0,frag=我
while i < N and frag in self.FREQ: # 当传入的词,在FREQ中时,就给tmplist赋值,构建字开始可能去往的所有的路径列表
if self.FREQ[frag]: #每个词,在FREQ中查找,查到,则将下标传入templist中
tmplist.append(i) #添加词语所在位置
i += 1 #查找我,后继续查找“我们”是否也在语料库中,直到查不到推出循环
frag = sentence[k:i + 1] #截取传入值得词语,i=1,时截取 我,i=2时截取我们
if not tmplist: #当传入值,在语料库中查询不到时,
tmplist.append(k)
DAG[k] = tmplist #赋值DAG 词典
return DAG计算全局概率Route ,基于词频最大切分组合
函数calc(self, sentence, DAG, route)就是计算概率的过程。其中语句 xrange(N - 1, -1, -1)是从句子的末尾开始计算,
route[idx] = max((log(FREQ.get(sentence[idx:x + 1]) or 1) - logtotal + route[x + 1][0], x) for x in DAG[idx])
max函数返回的是一个元组,计算方法是log(freq/total)+后一个字得到的最大概率路径的概率。这里即为动态规划查找最大概率路径。注意的是动态规划的方向是
从后往前。
#动态规划查找最大概率路径
def calc(self, sentence, DAG, route):
N = len(sentence)
route[N] = (0, 0) #route[N]:最大路径的值,(0,0):当前这个词的末尾坐标
# total 为dict.txt词表中,共有多少个词,共60101967 个词语
# 对概率值取对数之后的结果(可以让概率相乘的计算变成对数相加,防止相乘造成下溢)
logtotal = log(self.total)
# 从后往前遍历句子 反向计算最大概率
for idx in xrange(N - 1, -1, -1):
# 列表推倒求最大概率对数路径
# route[idx] = max([ (概率对数,词语末字位置) for x in DAG[idx] ])
# 以idx:(概率对数最大值,词语末字位置)键值对形式保存在route中
# route[x+1][0] 表示 词路径[x+1,N-1]的最大概率对数,
# [x+1][0]即表示取句子x+1位置对应元组(概率对数,词语末字位置)的概率对数
route[idx] = max((log(self.FREQ.get(sentence[idx:x + 1]) or 1) -
logtotal + route[x + 1][0], x) for x in DAG[idx])route计算返回结果为:{0: (-39.59958487630383, 1), 1: (-40.47334553305173, 1), 2: (-33.188277160361466, 3), 3: (-31.88719763919758, 3), 4: (-24.955566907701893, 4), 5: (-16.81294083908711, 6), 6: (-7.232624376933066, 6), 7: (0, 0)}
可根据route分词得到 “我们, 一起, 学, 猫叫”
智能推荐
jieba分词原理整理
一 工具简介 jieba 是一个基于Python的中文分词工具:https://github.com/fxsjy/jieba 对于一长段文字,其分词原理大体可分为三部: 1.首先用正则表达式将中文段落粗略的分成一个个句子。 2.将每个句子构造成有向无环图,之后寻找最佳切分方案。 3.最后对于连续的单字,采用HMM模型将其再次划分。 二 模式介绍 jieba分词分为“默认模式&rdquo...
NLP 使用jieba分词
相比于机械法分词法,jieba联系上下文的分词效果更好。 同时使用HMM模型对词组的分类更加准确。 测试对如下文本的分词效果 南门街前段时间经过整改劝阻摆摊占道的情况改善了很多,但是情况好了几天又慢慢的和以前一样了,只要有人带头 后面慢慢又摆出来,很多商户现在干脆用钩子把一些货物挂门口屋檐下的电线上,上有政策下就有对策,城管来检查就稍微好点,城管一走又摆出来又是老样子,希望有关部门采取强硬点的措施...
jieba分词原理
1. 原理 (1)基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG) (2)采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合 (3)对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法 2. 详细解释 2.1. 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 结巴分词自带...
jieba分词小案例
源数据集...

词云_jieba分词
词云_jieba分词 本篇是对词云的代码展示,详细...
猜你喜欢
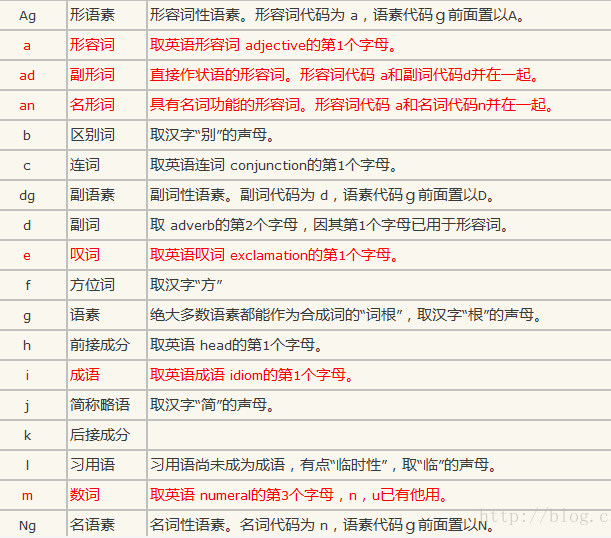
jieba分词词性标注
1.jieba可对分词后的单词进行词性标注,比如动词、名词还是形容词等等。词性类别详细列表: 2.工具库调用 其中,allowPOS就是过滤出来的词性列表。...
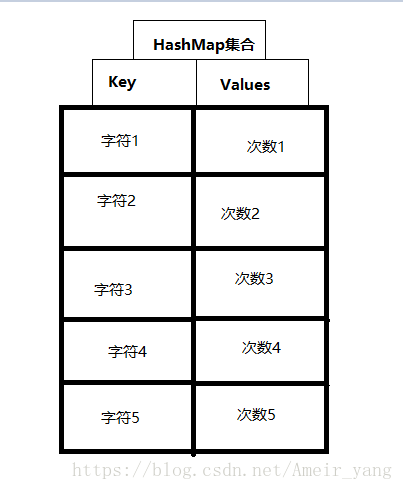
利用HashMap等双列集合,统计字符串中字符出现的次数 。
双列集合HashMap中存储的方式: HashMap<Character, Integer> hm = new HashMap<>() ; Key类型为:Character ; Values类型为:Integer ; 实现代码: ...
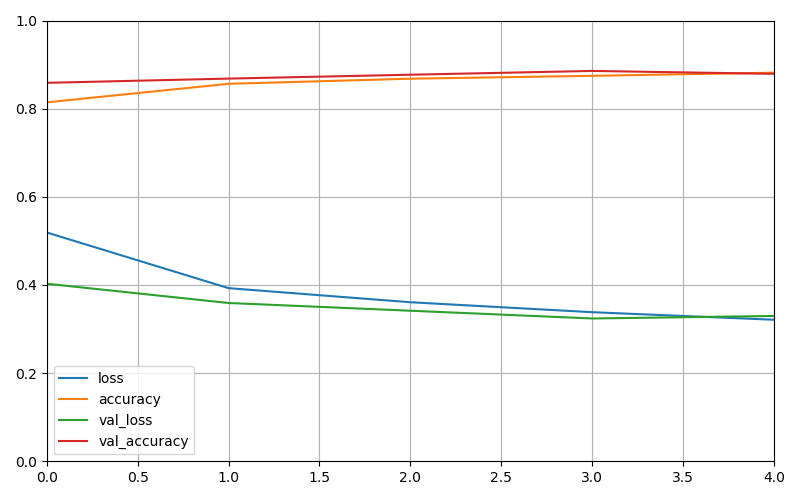
深度学习——tensorflow教程(一)
目标 教程基于tensorflow2.0进行编写 建立一个对图像进行分类的神经网络。 训练此神经网络。 最后,评估模型的准确性。 代码 模型结构 训练过程...
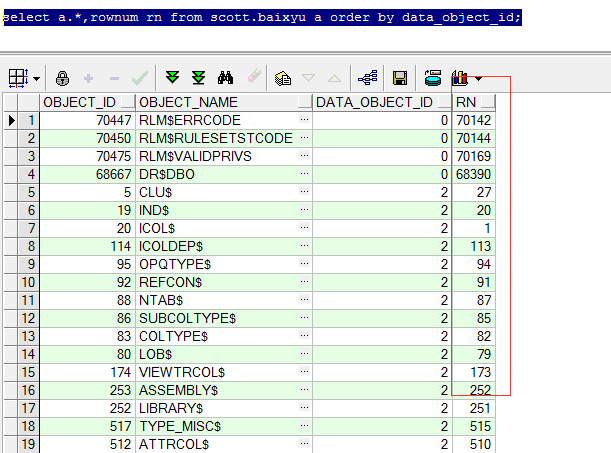
分页问题
今天看了阿里云的一篇文章,提到了关于分页的问题,之前我也没有注意到过。 create table baixyu as select object_id,object_name,data_object_id from dba_objects; “`...
JVM 性能调优 jstack
JVM 性能调优 jstack Jstack是Jdk自带的线程跟踪工具,用于打印指定Java进程的线程堆栈信息 命令 jstack pid > dump文件名 如 查看pid命令 查看进程下哪些线程占用了高的cpu 线程状态 状态名称 说明 NEW 初始状态,线程被构建,但是还没有调用start()方法 RUNNABLE 运行状态,Java线程将操作系统中的就绪和运行两种状态笼统地称作&ld...